Loop Hoisting
在上篇文章中,提到 Loop Hoisting ,这是一个常见的编译器优化项。我们总是能通过汇编代码等低级语言来“窥探”代码实际是怎么“指示”硬件运行的(这边文章不会涉及到详细的汇编内容,但是会用C#反编译后得到的汇编代码来辅助说明)。如果你看过我前面的几篇文章,会发现我用了大量反编译后的汇编代码来辅助说明,毕竟,千言不如实际的“证据”有说服力。
言归正传,Loop Hoisting,循环提升(粗略的翻译),编译器对循环代码中 loop-invariant 的代码提取出循环体外,防止循环结构内CPU对主存的重复读取。这很好理解,减少 CPU 与主存之间的 IO 次数,能有效提升程序的运行效率。观察下面的例子:
1 | namespace loop_hoisting |
很简单的一个例子,遍历列表且赋值。
LoopHoistTest 函数的循环判断里,直接读取列表的长度,编译器在碰到这种情况,会对其进行优化,将对列表长度的读取进行提升(Hoist),在循环体入口处缓存列表长度,并以此为判断依据,也就是说,从汇编代码的角度,循环判断始终去寄存器中读取缓存的列表长度信息,而不是每次都到主存中读取,以此来提到运行效率。另外,x+y很明显也是一段 loop-invariant 代码,相似地,编译器会将 x+y 的值缓存在某个通用寄存器内,并以此做赋值运算。编译器优化后的代码,就相当于:
1 | namespace loop_hoisting |
观察汇编代码:
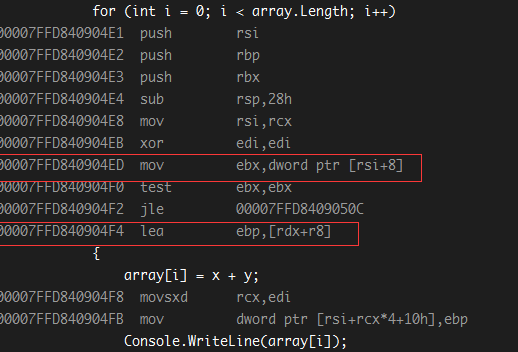
第一个红色框选的汇编代码:
1 | mov ebx,dword ptr [rsi+8] //将rsi寄存器值加上8的偏移量指向的主存中的值复制到ebx通用寄存器 |
其中
rsi 寄存器中的值就是主存中 array 的地址,偏移的8位指向 length 字段,这段指令将数值中的长度信息储存在 ebx 通用寄存器中,并且在以后的 cmp 指令中使用,而不是直接与主存中的内容比较。
1 | lea ebp,[rdx+r8] //将 rdx 和 r8 寄存器中的值相加并传送到 ebp 寄存器 |
其中,
rdx 和 r8 寄存器分别储存着 x 和 y 的值,两者的和被储存在 ebp 寄存器,以后的指令都使用这个寄存器中的值,不再重复计算。
当然,并不是所有的循环代码都可以被优化,这涉及到 Loop-invariant 条件的判定,我们下篇文章再讲。