Tags for the past Two years

程序在加载 C++/CLI 动态库的时候,出现 FileLoadException,常见错误是其中某些依赖没有找到,这个时候异常信息应该是类似:一个xxx的依赖没有找到;这个问题很好解决,确定缺少的依赖补充上就可以了,可以使用 dumpbin 工具查看相关的依赖:1
dumpbin /dependents target.dll
但是,有一种比较隐晦的错误导致动态库加载失败,错误提示:未能加载由xxx.dll导入的过程,除了这些,几乎没有什么有用的错误信息让我们来确定到底出现了什么问题。一般来说,按照目前我遇到的问题,这个一般都是对应的库文件调用了当前平台不支持的api导致的。当然,这个问题不易在开发的机器上发现,因为能调用到这个api就代表调试机器上有对应平台版本的SDK,一般如果前期没有发现到这个问题,那么问题被发现时肯定是在生成环境,所以需要开发人员注意调用接口的支持平台。
要定位是什么接口导致的问题,需要借助其他的调试工具来排查。微软的 Windows SDK 提供了对应的工具 gflags.exe,借助这个工具,我们可以在调试的过程中看到详细的动态库加载信息,在这些信息中可以定位到底是什么接口导致库文件加载失败。当然,你需要在出现问题的机器上使用这个工具进行操作,并通过 Visual Studio 进行远程调试。
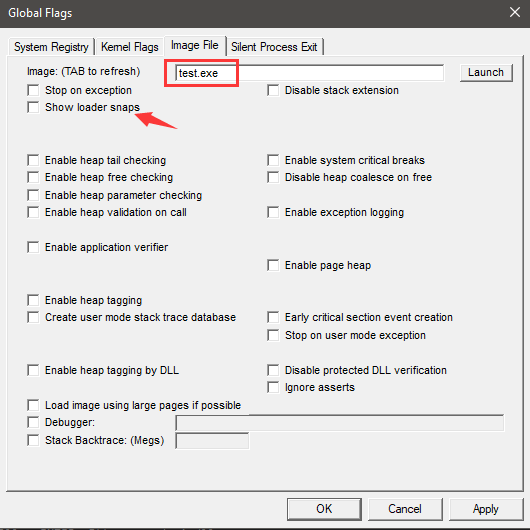
如上图显示,通过输入你程序的名字和开启 Show loader snaps 开关,应用后使用 Visual Studio 进行调试,可以在输出窗口看到详细的加载信息:

在上一篇文章中,我们已经对 Loop Invariant 概念有一个简单的了解,在文章的最后提到的 Loop Invariant 将在这篇文章做一个简单的介绍。
如果你了解 C# 程序的运行,应该知道 C# 代码先被编译器编译为 MSIL 中间代码,在实际运行的时候才通过 JIT 编译器将 MSIL 代码编译成机器代码并运行。因此,编译器有两个时段可以对代码进行优化:
在上篇文章中,提到 Loop Hoisting ,这是一个常见的编译器优化项。我们总是能通过汇编代码等低级语言来“窥探”代码实际是怎么“指示”硬件运行的(这边文章不会涉及到详细的汇编内容,但是会用C#反编译后得到的汇编代码来辅助说明)。如果你看过我前面的几篇文章,会发现我用了大量反编译后的汇编代码来辅助说明,毕竟,千言不如实际的“证据”有说服力。
在 C# 的语言规范中 ECMA-334,对于Volatile关键字的描述:
15.5.4 Volatile fields
When a field-declaration includes a volatile modifier, the fields introduced by that declaration are volatile fields. For non-volatile fields, optimization techniques that reorder instructions can lead to unexpected and unpredictable results in multi-threaded programs that access fields without synchronization such as that provided by the lock-statement (§13.13). These optimizations can be
performed by the compiler, by the run-time system, or by hardware. For volatile fields, such reordering optimizations are restricted:
- A read of a volatile field is called a volatile read. A volatile read has “acquire semantics”; that is, it is guaranteed to occur prior to any references to memory that occur after it in the instruction sequence.
- A write of a volatile field is called a volatile write. A volatile write has “release semantics”; that is, it is guaranteed to happen after any memory references prior to the write instruction in the instruction sequence.
简单来说,对于常规字段,由于代码优化而导致指令顺序改变,如果没有进行一定的同步控制,在多线程应用中可能会导致意想不到的结果,而造成这种意外的原因可能是编译器优化、运行时系统的优化或者因为硬件的原因(即CPU和主存储器的通信模型)。可变(volatile)字段会限制这种优化的发生,在这里引入两个定义:
获取语义。即,其可以保证对于可变字段的内存读取操作一定发生在其后内存操作指令的前面。进一步解释,与 Thread.MemoryBarrier 类似,获取语义会保证在读取可变字段指令前的指令可以跨越它出现在它后面,但是相反地,在它后面的指令不能跨越它出现在它的前面。例子:释放语义。即,其可以保证对于可变字段的写操作发生在其前面指令执行之后,但是在它之后的指令可以跨域它提前执行。有时候我们使用递归来解决一些特定的问题,但是使用递归需要注意不要导致栈溢出,这是使用递归的一个常见问题,对于规模足够大的问题,使用递归必定会导致栈溢出。通常,我们可以通过尾递归进行优化,尾递归可以避免栈溢出的问题(暂且这样认为)。
尾递归并不是什么新奇的东西,理解起来很简单,对于递归,如果上层调用的返回结果不依赖子调用的结果,那么,这就是一个尾递归。例如:
从上面的例子分析,代码依旧会导致栈溢出,不是吗?是的,聪明的你答对了。那为什么说尾递归可以避免栈溢出问题?当然,从刚才的结论看,这个问题提的并不准确,尾递归并不能避免栈溢出问题。
仔细想想,尾递归结构和循环结构是类似的,上面的尾递归可以写成:
在一些应用的开发场景中,例如,大量的数据处理、需要对数据进行大量的转换和过滤,使用管道和Filter是一个很好的选择。对于这种应用场景,一般都需要处理业务足够灵活,并且足够健壮。想象一下,为了实现相应的过滤功能,使用大量的if或者switch case,日后维护这套代码的人估计也会抓狂的吧,单元测试编写起来,应该也够呛吧。
Mlt framework 是一个开源跨平台的多媒体处理框架,使用模块化的设计,集成了大量的业界领先的视频处理框架,如ffmpeg,良好的设计,可以方便的集成自己的模块进去,利用它,你可以实现自己的 Adobe Premiere 等非线性多媒体编辑软件或者视频播放器,简单几句代码为视频添加炫酷的转场效果和滤镜。
由于跨平台,项目通过configure的方式来管理工程,对于学习来说多媒体框架来说,调试起来并不方便,我整理了CMake的脚本,可以通过cmake来生成我们熟悉的 Visual Studio 或者 Xcode
工程,方便调试。
在阅读下面文章之前,请确保你有一定的 MinGW 工具链使用经验。